电商用户画像分析(电商用户群体分类标准)
特别说明:
本文主要包括两个部分:
用户画像标签(第一至第四)用户画像标签的应用(第五及以后)一、背景介绍:
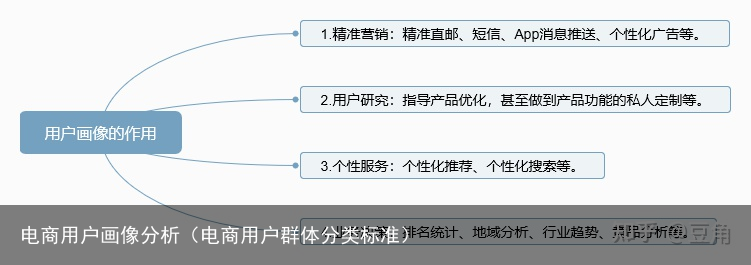
用户画像是通过分析用户的基础信息、特征偏好、社会属性等各维度的数据,刻画出用户的信息全貌,它是建立在一系列属性数据之上的目标用户模型。用户画像的本质是一个用以描述用户需求的工具。用户画像一般是产品设计、运营人员从用户群体中抽象出来的典型用户,从中可以挖掘用户价值,提供个性化推荐、精准营销等服务。
主要应用有:
二、理解数据与分析思路
1.导入使用的包:
import pandas as pd import numpy as np # 画图的包 import matplotlib.pyplot as plt # 字体格式设置的包 import matplotlib matplotlib.rcParams[font.sans-serif] = [SimHei] matplotlib.rcParams[font.family]=sans-serif matplotlib.rcParams[axes.unicode_minus] = False # 解决负号-显示为方块的问题 # 连接数据库的包 import sqlalchemy as pysql # 时间格式转化的包 from datetime import datetime #内存回收的模块 import gc # 系统模块 import os2.导入并理解数据:
# 读取用户数据 user_data = pd.read_excel(r.\user_data.xlsx) user_data = user_data.loc[:,~user_data.columns.str.contains(Unnamed)].reset_index(drop=True)#去掉读取数据多出来的Unamed列 user_data # 读取订单数据
order_data = pd.read_excel(rD:.\order_data.xlsx)
order_data
# 读取订单数据
order_data = pd.read_excel(rD:.\order_data.xlsx)
order_data
说明:order_data共有五个字段,分别为,其中behavior_type中1为浏览,2为收藏,3为加购,4为购买
3.分析维度:

三、数据预处理:
# 保持源数据不动 order_data_copy = order_data.copy() order_data_copy.info() # 数据全部非空,数据格式也都没问题
数据全部非空,数据格式也都没问题
order_data_copy. user_id.nunique() # 数据没有重复222
# 时间格式转换及提取 order_data_copy[time] = pd.to_datetime(order_data_copy[time]) order_data_copy[date] = order_data_copy[time].dt.date# 提取出来是object order_data_copy[time] = order_data_copy[time].dt.hour order_data_copy[date] = pd.to_datetime(order_data_copy[date]) order_data_copy # 将时段分为凌晨、上午、中午、下午、晚上,左开右闭区间
bins = [-1,5,10,13,18,23]
labels = [凌晨,上午,中午,下午,晚上]
order_data_copy[hour] = pd.cut(order_data_copy[time],bins=bins,labels=labels)
order_data_copy
# 将时段分为凌晨、上午、中午、下午、晚上,左开右闭区间
bins = [-1,5,10,13,18,23]
labels = [凌晨,上午,中午,下午,晚上]
order_data_copy[hour] = pd.cut(order_data_copy[time],bins=bins,labels=labels)
order_data_copy
3.制作用户标签表:
# 生成用户标签表,制作好的标签都加入这个表中 label = user_data.copy() label.head()
四、分析过程:
1、用户活跃的时间
1.1 用浏览活跃时间段计算加工流程:
a、提取 behavior_type=1 的用户浏览数据b、然后根据 用户id+时间段 分组计数,并且求出最大值c、获取用户id+最活跃时间段,如果有多个最活跃时间段,则进行逗号拼接behavior_type 的内容
浏览:behavior_type=1收藏:behavior_type=2加购:behavior_type=3购买:behavior_type=4# 选取用户浏览数据,按照用户id+用户浏览时段hour分组统计用户各个浏览时段的次数 user_browse = order_data_copy[order_data_copy[behavior_type]==1].groupby(by=[user_id,hour]).item_id.count().reset_index() # 按照用户id分组,选取用户浏览次数的最大值 user_browse_max = user_browse.groupby(user_id).item_id.max().reset_index() # 左关联用户浏览次数表和用户浏览次数最大值的表,统计用户浏览活跃时段,如果左表次数跟右表次数相同的数量多于1条,则用户可能有多个时段一样活跃 user_browse_merge = pd.merge(user_browse,user_browse_max,how=left,on=user_id) #选取各用户浏览次数最多的时段,如有并列最多的时段,用 - 连接 browse_hour = user_browse_merge.loc[user_browse_merge[item_id_x] == user_browse_merge[item_id_y],hour].groupby(user_browse_merge[user_id]).agg(lambda x : -.join(x)).reset_index() # 讲上一个cell的结果及放到用户标签表中 labels = pd.merge(label,browse_hour,how=left,on=user_id) labels.rename(columns={hour:browse_hour},inplace=True)1.2 用户购买活跃时间段
计算加工流程:
a、提取 behavior_type=4 的用户购买数据b、然后根据 用户id+时间段 分组计数,并且求出最大值c、获取 用户id+最活跃时间段,如果有多个最活跃时间段,则进行逗号拼接# 加工逻辑与用户浏览活跃时段相同 # 选取用户购买数据,按照用户id+用户浏览时段hour分组统计用户各个购买时段的次数 user_buy = order_data_copy[order_data_copy[behavior_type]==4].groupby(by=[user_id,hour]).item_id.count().reset_index() user_buy_max = user_buy.groupby(user_id).item_id.max().reset_index() # 左关联用户购买次数表和用户购买次数最大值的表,统计用户购买活跃时段,如果左表次数跟右表次数相同的数量多于1条,则用户可能有多个时段一样活跃 user_buy_merge = pd.merge(user_buy,user_buy_max,how=left,on=user_id) #选取各用户购买次数最多的时段,如有并列最多的时段,用 - 连接 buy_hour = user_buy_merge.loc[user_buy_merge[item_id_x] == user_buy_merge[item_id_y],hour].groupby(user_buy_merge[user_id]).agg(lambda x : -.join(x)).reset_index() # 讲上一个cell的结果及放到用户标签表中 labels = pd.merge(labels,buy_hour,how=left,on=user_id) labels.rename(columns={hour:buy_hour},inplace=True) labels.head()
2、关于类目的用户行为
2.1 浏览最多的类目
计算加工流程:
提取 behavior_type=1 的用户购买数据然后根据 用户id+类目 分组计数,并且求出最大值获取 用户id+浏览最多的类目,如果有多个类目,则进行逗号拼接# 选取数据集,并分组统计item_id的次数,因为多个item_id归属于一个item_category,所以只需要统计item_id的次数就是浏览该类目的次数 browse_category = order_data_copy[order_data_copy[behavior_type] == 1].groupby([user_id,item_category]).item_id.count().reset_index() # 浏览次数最多的类目 browse_category_max = browse_category.groupby(user_id).item_id.max().reset_index() # 拼接并列次数的类目 browse_category_merge = pd.merge(browse_category,browse_category_max,how=left,on=user_id) # 转换字段格式,不然后面会报错 browse_category_merge[item_category] = browse_category_merge[item_category].astype(str) # 最终汇总表 browse_category_most = browse_category_merge.loc[browse_category_merge[item_id_x] ==browse_category_merge[item_id_y],item_category ].groupby(browse_category_merge[user_id]).agg(lambda x : -.join(x)).reset_index() # 修改列名,见名知意 browse_category_most.rename(columns={item_category:browse_category_most},inplace=True) # 放入标签表 labels = pd.merge(labels,browse_category_most,how=left,on=user_id) # 查看最新标签表 labels.head()
2.2 收藏最多的类目
提取 behavior_type=2 的用户购买数据然后根据 用户id+类目 分组计数,并且求出最大值获取 用户id+收藏最多的类目,如果有多个类目,则进行逗号拼接collect_category = order_data_copy[order_data_copy[behavior_type] == 2].groupby([user_id,item_category]).item_id.count().reset_index() collect_category_max = collect_category.groupby(user_id).item_id.max().reset_index() collect_category_merge = pd.merge(collect_category,collect_category_max,how=left,on=user_id) collect_category_merge[item_category] = collect_category_merge[item_category].astype(str) collect_category_most = collect_category_merge.loc[collect_category_merge[item_id_x] ==collect_category_merge[item_id_y],item_category ].groupby(collect_category_merge[user_id]).agg(lambda x : -.join(x)).reset_index() collect_category_most.rename(columns={item_category:collect_category_most},inplace=True) labels = pd.merge(labels,collect_category_most,how=left,on=user_id) labels.head()
2.3 加购最多的类目
提取 behavior_type=3 的用户购买数据然后根据 用户id+类目 分组计数,并且求出最大值获取 用户id+加购最多的类目,如果有多个类目,则进行逗号拼接cart_category = order_data_copy[order_data_copy[behavior_type] == 2].groupby([user_id,item_category]).item_id.count().reset_index() cart_category_max = cart_category.groupby(user_id).item_id.max().reset_index() cart_category_merge = pd.merge(cart_category,cart_category_max,how=left,on=user_id) cart_category_merge[item_category] = cart_category_merge[item_category].astype(str) cart_category_most = cart_category_merge.loc[cart_category_merge[item_id_x] ==cart_category_merge[item_id_y],item_category ].groupby(cart_category_merge[user_id]).agg(lambda x : -.join(x)).reset_index() cart_category_most.rename(columns={item_category:cart_category_most},inplace=True) labels = pd.merge(labels,cart_category_most,how=left,on=user_id) # labels.head()结果:略
2.4 购买最多的类目
提取 behavior_type=4 的用户购买数据然后根据 用户id+类目 分组计数,并且求出最大值获取 用户id+购买最多的类目,如果有多个类目,则进行逗号拼接buy_category = order_data_copy[order_data_copy[behavior_type] == 2].groupby([user_id,item_category]).item_id.count().reset_index() buy_category_max = buy_category.groupby(user_id).item_id.max().reset_index() buy_category_merge = pd.merge(buy_category,buy_category_max,how=left,on=user_id) buy_category_merge[item_category] = buy_category_merge[item_category].astype(str) buy_category_most = buy_category_merge.loc[buy_category_merge[item_id_x] ==buy_category_merge[item_id_y],item_category ].groupby(buy_category_merge[user_id]).agg(lambda x : -.join(x)).reset_index() buy_category_most.rename(columns={item_category:buy_category_most},inplace=True) labels = pd.merge(labels,buy_category_most,how=left,on=user_id) labels.head()
3、30天用户行为
3.1 近30天购买次数
提取 behavior_type=4 的用户购买数据然后根据 用户id 分组计数,得到结果# 选取最近1个月的时间,因为这里的数据源时间范围是2014-11-18到2014-12-18,所以我们以2014-12-19为当前时间 order_data_30 = order_data_copy.loc[(pd.to_datetime(20141119) -order_data_copy[date]).dt.days <= 30,:] #指定列 order_data_30.head()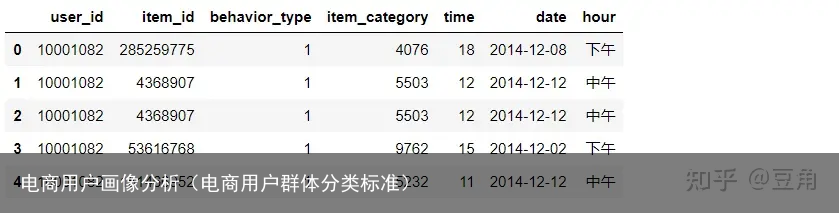 # 最近30天用户购买次数
buy_counts_30 = order_data_30[order_data_30[behavior_type] == 4].groupby(user_id).item_id.count().reset_index()
buy_counts_30.rename(columns={item_id:buy_counts_30},inplace=True)
# 将用户今30天购买次数加入标签表
labels = pd.merge(labels,buy_counts_30,how=left,on=user_id)
# 最近30天用户购买次数
buy_counts_30 = order_data_30[order_data_30[behavior_type] == 4].groupby(user_id).item_id.count().reset_index()
buy_counts_30.rename(columns={item_id:buy_counts_30},inplace=True)
# 将用户今30天购买次数加入标签表
labels = pd.merge(labels,buy_counts_30,how=left,on=user_id)结果:略
3.2 近30天加购次数
提取 behavior_type=3 的用户购买数据然后根据 用户id 分组计数,得到结果cart_counts_30 = order_data_30[order_data_30[behavior_type] == 3].groupby(user_id).item_id.count().reset_index() cart_counts_30.rename(columns={item_id:cart_counts_30},inplace=True) labels = pd.merge(labels,cart_counts_30,how=left,on=user_id) labels.head(1)
3.3 近30天活跃天数
提取所有用户购买数据然后根据 用户id 分组计数,统计不同日期的天数active_days_30 = order_data_30.groupby(user_id)[date].nunique().to_frame().reset_index() active_days_30.rename(columns={date:active_days_30},inplace=True) labels = pd.merge(labels,active_days_30,how=left,on=user_id) labels.head(1)4、7天用户行为
4.1 近7天购买次数
提取 behavior_type=4 的用户购买数据然后根据 用户id 分组计数,得到结果# 选取最近7天的订单数据 order_data_7 = order_data_copy[(pd.to_datetime(20141219) - order_data_copy[date]).dt.days <= 7] order_data_7.head()buy_counts_7 = order_data_7[order_data_7[behavior_type] == 4].groupby(user_id)[item_id].count().reset_index() buy_counts_7.rename(columns={item_id:buy_counts_7},inplace=True) labels = pd.merge(labels,buy_counts_7,how=left,on=user_id) # labels.head()结果:略
4.2 近7天加购次数
提取 behavior_type=3 的用户加购数据然后根据 用户id 分组计数,得到结果cart_counts_7 = order_data_7[order_data_7[behavior_type] == 3].groupby(user_id)[item_id].count().reset_index() cart_counts_7.rename(columns={item_id:cart_counts_7},inplace=True) labels = pd.merge(labels,cart_counts_7,how=left,on=user_id)结果:略
4.3 近7天活跃天数
获取每个用户近7天里面的日期数据,不区分用户行为有记录就算去重统计有多少个日期active_days_7 = order_data_7.groupby(user_id)[date].nunique().to_frame().reset_index() active_days_7.rename(columns={date:active_days_7},inplace=True) labels = pd.merge(labels,active_days_7,how=left,on=user_id) labels.head(1)5.最后一次行为距今天数(今天取2014/12/19)
5.1 上次浏览距今天数
提取 behavior_type=1 的用户浏览数据,获取里面最大的一个日期时间,然后用现在时间相减得到天数添加到标签内容里面去last_browse_days =order_data_copy[order_data_copy[behavior_type] == 1].groupby([user_id]).date.max().map(lambda x :(datetime.strptime(2014-12-19,%Y-%m-%d) - x).days).reset_index() last_browse_days.rename(columns ={date:last_browse_days},inplace=True) labels = pd.merge(labels,last_browse_days,how=left,on=user_id)结果:略
5.2 上次加购距今天数
提取 behavior_type=3 的用户加购数据,获取里面最大的一个日期时间,然后用现在时间(2014-12-19)相减得到天数添加到标签内容里面去last_cart_days =order_data_copy[order_data_copy[behavior_type] == 3].groupby([user_id]).date.max().map(lambda x :(datetime.strptime(2014-12-19,%Y-%m-%d) - x).days).reset_index() last_cart_days.rename(columns ={date:last_cart_days},inplace=True) labels = pd.merge(labels,last_cart_days,how=left,on=user_id) labels.head(1)6.最近两次购买间隔天数
提取 behavior_type=4 的用户购买数据,对 用户id+日期 进行分组,统计记录数再对上面得到的数据根据 用户id 进行分组,然后对日期进行一个偏移,获取添加到标签内容里面去# 统计用户访问日期及次数 interval_days =order_data_copy[order_data_copy[behavior_type] == 4].groupby([user_id,date])[item_id].count().reset_index() # 计算日期差 buy_interval_days = interval_days.groupby(user_id)[date].apply(lambda x :x.sort_values().diff(1).dropna().tail(1).dt.days).reset_index() # 删除多余列 del buy_interval_days[level_1] # 改列名 buy_interval_days.rename(columns={date:buy_interval_days},inplace=True) 放入标签表 labels = pd.merge(labels,buy_interval_days,how=left,on=user_id) labels.head(1)7.是否有商品浏览未下单
提取 behavior_type=1 的浏览数据 和 behavior_type=4 的用户购买数据,根据 用户id+商品id+用户行为 来进行分组,统计每个用户对每个商品的浏览情况和购买情况判断每一个用户对于每一个商品是否存在,浏览但是未购买的行为,如果有那新建一个字段的值记为1,没有则为0再根据 用户id 进行分组,统计每个用户的 浏览但未购买 的次数,如果大于0则为 是,否则为 否browse_buy = order_data_copy[(order_data_copy[behavior_type] == 1) | (order_data_copy[behavior_type] ==4)] browse_buy_p = browse_buy.pivot_table(index=[user_id,item_id],columns=[behavior_type],values=[time],aggfunc=[count],fill_value=0) browse_buy_p.columns=[browse,buy]# 定义函数,判断多列,生成新的一列 def judge(a,b): if a >0 and b == 0: return 1 else: return 0 browse_buy_p[browse_not_buy] = browse_buy_p.apply(lambda x : judge(x.browse,x.buy),axis=1) browse_buy_p.head()# 整理存入标签表 browse_buy_pp = browse_buy_p.groupby(user_id)[browse_not_buy].sum().reset_index() browse_buy_pp[browse_not_buy] = browse_buy_pp[browse_not_buy].map(lambda x : 是 if x > 0 else 否) labels = pd.merge(labels,browse_buy_pp,how=left,on=user_id) # labels.head()结果:略
8.是否有商品加购未下单
提取 behavior_type=3 的加购数据 和 behavior_type=4 的用户购买数据,根据 用户id+商品id+用户行为 来进行分组,统计每个用户对每个商品的加购情况和购买情况判断每一个用户对于每一个商品是否存在,加购但是未购买的行为,如果有那新建一个字段的值记为1,没有则为0再根据 用户id 进行分组,统计每个用户的 加购但未购买 的次数,如果大于0则为 是,否则为 否# 代码逻辑与上面一样 cart_buy = order_data_copy[(order_data_copy[behavior_type] == 3) | (order_data_copy[behavior_type] ==4)] cart_buy_p = cart_buy.pivot_table(index=[user_id,item_id],columns=[behavior_type],values=[time],aggfunc=[count],fill_value=0) cart_buy_p.columns=[cart,buy] def judge(a,b): if a >0 and b == 0: return 1 else: return 0 cart_buy_p[cart_not_buy] = cart_buy_p.apply(lambda x : judge(x.cart,x.buy),axis=1) cart_buy_pp = cart_buy_p.groupby(user_id)[cart_not_buy].sum().reset_index() cart_buy_pp[cart_not_buy] = cart_buy_pp[cart_not_buy].map(lambda x : 是 if x > 0 else 否) labels = pd.merge(labels,cart_buy_pp,how=left,on=user_id) labels.head()9、用户属性标签
9.1 是否复购用户
提取 behavior_type=4 的用户购买数据如果计数大于1则有复购,否则没有复购buy_again = order_data_copy[order_data_copy[behavior_type]==4].groupby(user_id)[item_id].count().reset_index() buy_again.rename(columns={item_id:buy_again},inplace=True) buy_again[buy_again] = buy_again[buy_again].map(lambda x :是 if x >1 else 否 if x==1 else 未购买) labels = pd.merge(labels,buy_again,how=left,on=user_id) labels.head(1)9.2 访问活跃度
获取标签的统计值 active_days_30近30天活跃人数情况对活跃次数分组计数,也就是得到了访问次数和访问人数的情况进行绘图得到趋势图如果访问活跃度超过20,则定义为“高”,否则定义为“低”# 对活跃次数分组计数,也就是得到了访问次数和访问人数的情况 active_days_30[active_days_30].value_counts().sort_index().plot(title=30天内访问天数与访问人数的关系 ,fontsize=15, xlabel=访问天数, ylabel=访问人数)总体上看,访问天数多的访客比访问天数少的访客数量多,且以20次左右为拐点,因此定义访问天数小于20次的为低活跃,访问天数大于等于20次的定义为高活跃。此定义只是从用户的分布角度出发,工作中当从业务出发定义是否活跃
labels[active_level_30] = labels[active_days_30].apply(lambda x : 高 if x>20 else 低) labels.head(1)9.3 购买的品类是否单一
buy_cate_single = order_data_copy[order_data_copy[behavior_type] == 4].groupby(user_id).item_category.count().reset_index() buy_cate_single.rename(columns={item_category:buy_cate_single},inplace=True) buy_cate_single[buy_cate_single] = buy_cate_single[buy_cate_single].map(lambda x :否 if x >1 else 是 if x==1 else 未购买) labels = pd.merge(labels,buy_cate_single,how=left,on=user_id) labels.head(1)9.4 用户价值分组
获取标签的统计值 last_buy_days 得到上次距今购买天数对购买天数进行统计计数,得到 last_buy_level绘制购买天数last_buy_level 和 购买人数的图形走势对购买天数进行分类,如果大于8天则为“低”,反之为“高”RFM:
最近一次消费 (Recency)消费频率 (Frequency)消费金额 (Monetary)labels[last_buy_days].value_counts().sort_index().plot(xlabel = 最后一次购买距今天数, ylabel = 人数, title = 最近购买间隔天数与人数的关系, fontsize = 15)注:访问异常的那天为双12
# 对购买天数进行分类,小于8天为高,大于8天为低 labels[last_buy_level] = labels[last_buy_days].apply(lambda x : 低 if x>8 else 高) # 合并用户最近购买天数水平和购买频次,组合成客户价值类型 labels[rfm_level] = labels[last_buy_level].str.cat(labels[active_level_30]) # sep参数可选 # 定义函数,判断 def user_rfm(x): if x == 高高: return 重要价值客户 elif x == 高低: return 重要深耕客户 elif x == 低高: return 重要唤回客户 else: return 即将流失客户 labels[user_rfm] = labels[rfm_level].apply(lambda x : user_rfm(x)) labels.head()# 删除多余列 labels.drop([last_buy_level,rfm_level],axis =1,inplace=True) # 存入数据库 engine = pysql.create_engine(mysql+pymysql://root:password@localhost:3306/database_name) labels.to_sql(用户画像标签表,con = engine,if_exists=replace, index=False)五、用户画像应用
1 业务场景
最近小家电类目的订单数量、产品浏览量、搜索数量等都有所下降, 现在运营同事计划对小家电类目进行一次季末促销活动,希望你能针对小家电的用户特征给出一些建议。
促销活动落地的方向:
活动的受众群体定位受众群体的偏好活动的推送时间2、分析过程:
# 从数据库读取用户行为数据表 engine = pysql .create_engine(mysql+pymysql://root:password@localhost:3306/database?charset=gbk) select = select * from 用户画像标签表 dt = pd.read_sql_query(sql=select,con=engine) dt.head(1)就是我们上面最后存入数据库的表
2.1 用户的基本属性
分析思路:
用户的性别分布用户的年龄分布用户的地域分布用户的婚育情况用户的学历和职业2.1.1 用户性别分布
dt.groupby(gender).user_id.count().plot.pie(figsize=(10,5), x= gender, y="user_id", autopct=%.2f%%, shadow= True, title=用户性别分布图)性别分布情况:
男多女少,但没有明显差别.2.1.2 用户的年龄分布
bins = [0,20,25,30,35,40,45,50,55,1000] labels = [(0-20],(20-25],(25-30],(30-35],(35-40],(40-45],(45-50],(50-55],55以上] dt[age_cut] = pd.cut(dt.age,bins= bins,labels=labels) dt.head(1)dt.groupby(age_cut).user_id.count().plot.bar(x =age_cut, y=user_id, title = 用户年龄分布图, figsize=(10,5), rot=0)年龄分布情况:
用户大都分布在25-40岁区间,尤以25-35最多。25以下和40以上的分布明显较少。2.1.3 用户的地域分布
# 按照省份统计 dt.groupby(province).user_id.count().sort_values().plot.barh(figsize=(10,5), x=user_id ,y=province, title=用户省份分布图)省份分布情况:
广东最多,其次北京、上海,前五有四个是沿海省份
# 按照城市统计 dt.groupby(city).user_id.count().sort_values().plot.barh(figsize=(10,5), x=user_id ,y=city, title=用户城市分布图)城市分布情况:
北上广深分布最多,且大都集中于沿海一二线城市2.1.4 用户的婚育情况
dt.groupby(marriage).user_id.count().plot.pie(figsize=(10,5), x= marriage, y="user_id", autopct=%.2f%%, shadow= True, title=用户婚育分布图)用户婚育情况:
大部分为已婚用户2.1.5 用户的学历和职业
# 学历 dt.groupby(eduction).user_id.count().sort_values(ascending=False).plot.bar(figsize=(10,5), x=user_id ,y=eduction, title=用户学历分布图, rot =0)用户学历分布情况:
基本是本科及以上学历
# 职业 dt.groupby(job).user_id.count().sort_values(ascending=False).plot.bar(figsize=(10,5), x=user_id ,y=job, title=用户职业分布图, rot =0)用户职业分布情况:
大部分为白领或互联网从业者2.1.6 总结
消费的典型用户基本特征:
年龄在30岁左右,男性为主,拥有本科及以上学历,从事白领或互联网职业,经济收入较高,思维开阔,比较追求生活品质,但由于大城市生活节奏快、压力较大,平时可能不会有太多时间和精力关注家庭生活。2.2 用户的浏览及购买行为属性
购买时间情况:
按星期统计按时间统计# 读取数据 dt1 = pd.read_excel(r.\order_data.xlsx) # 对时间做处理 dt1[time] = pd.to_datetime(dt1[time]) # dt1.time.head() dt1[hour] = dt1[time].dt.hour # dt1.hour.head() dt1[weekday] = dt1[time].dt.dayofweek +1# 周一=0 dt1.head()2.2.1 用户浏览时间分析
dt1_browse = dt1[dt1[behavior_type] == 1]2.2.1.1 周维度浏览情况分析
dt1_browse.groupby(weekday).user_id.count().plot(figsize=(10,5), x=weekday, y=user_id, title= 用户浏览时间周分布)用户浏览时间分布:
周二到周五浏览较多,其他时间较少2.2.1.2 时维度浏览情况分析
dt1_browse.groupby(hour).user_id.count().plot(figsize=(10,5), x=hour, y=user_id, title= 用户浏览时间日内分布, xticks=range(0,24))用户浏览时间日内分布:
21-22点最多,10-17一般,0-5最少小结
用户浏览时间分布特征:
周二、周五大量浏览,21-22浏览量最大2.2.2 用户购买时间分析
dt1_buy = dt1[dt1[behavior_type] == 4]2.2.2.1 周维度购买情况分析
dt1_buy.groupby(weekday).user_id.count().plot(figsize=(10,5), x=weekday, y=user_id, title= 用户购买时间周分布)用户周维度购买情况:
周二、周五为用户下单峰值,其他时间较少2.2.2.2 时维度购买情况分析
dt1_buy.groupby(hour).user_id.count().plot(figsize=(10,5), x=hour, y=user_id, title= 用户购买时间日内分布, xticks=range(0,24))用户购买日维度情况:
用户下单时间集中在21-22点小结
用户购买时间分布特征:
周二、周五大量下单,21-22下单量最大2.2.3 总结
用户大都喜欢在周二和周五晚上21-22点浏览下单
2.3 结论及建议
2.3.1 用户特征:
30岁左右已婚男性为主,本科及以上学历,从事互联网等收入较高的行业,他们喜欢在周二到周五的晚上10点左右下单,比较追求生活品质,关心家庭,但由于大城市生活节奏快、压力大,平时又没有时间在家庭生活上付出很多时间和精力。2.3.2 对于促销活动的建议:
文案:采取无性别风格的文案,突出产品对于家庭生活品质的提升,突出产品口碑。时间:活动应该选择在周二到周五的晚上8左右点进行推送